在2023 年 11 月 25 日举办的中国 DevOps 社区广州峰会上,小鹅通效能平台负责人王梓城分享了其团队从 0 到 1 建设 DevOps 体系的实践经验,赢得了在场听众的广泛共鸣。
背景
疫情期间小鹅通响应“停课不停学”的号召,肩负使命克服困难如期完成了产品交付。之后小鹅通在各行各业中被使用,随之而来的是幸福的烦恼——业务需求的爆炸式增长,打乱了原本产研规划的所有节奏,同时产研交付效率的问题变得尤为突出,被用户和业务部门反复提及。
此时,产研能力的建设得到了重视,公司成立了一个新的团队,专项解决产研交付效率的问题。
团队成立之初仅 3 人,一边忙着交接原有手上的业务,一边摸索能效提升的解法。在逐步解决一个个现实问题过程中,从不太了解 DevOps,渐渐深入了解并走上了 DevOps 实践的道路。
三个阶段
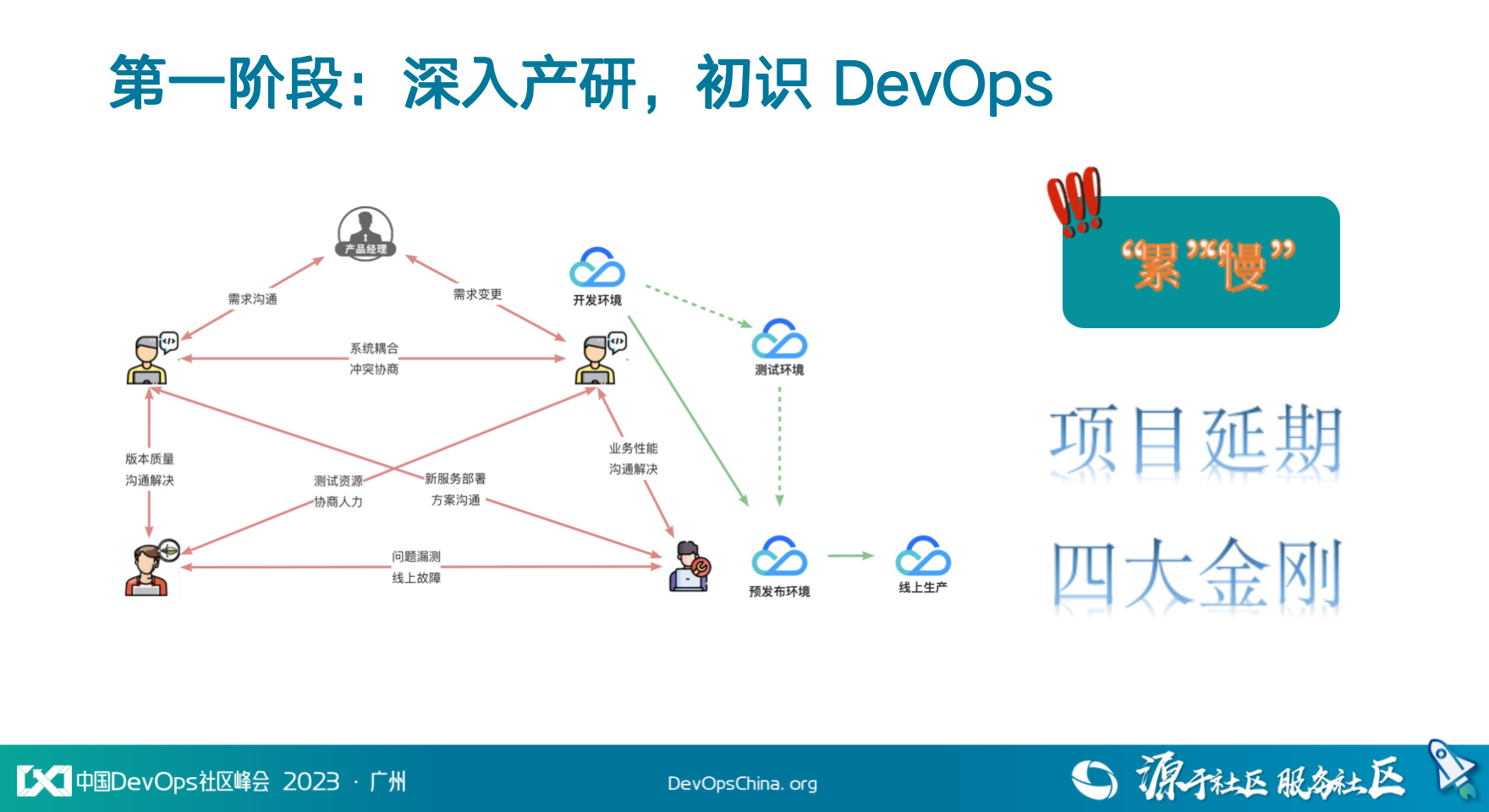
效能团队从原本的业务中心成立,起初只有 3 人,对业务情况也不是很清楚。带着使命花了近 2 个月时间完成原有业务交接的同时深入了解原有的全局产研状态。在开发 > 测试 > 运维、需求规划 > 开发迭代 > 最终测试 > 发布上线的整个过程中,了解到研发团队为了支持业务的快速迭代、减少测试验证轮次,在开发环境验证通过后,直接上线至预发布环境验证后全网发版。在这种模式下各个角色之间相互吐槽,印象中被反馈最多的直观感受是 2 个字 ——“累”、“慢”;在产研侧听到过最多的2个词则是“项目延期”与“四大金刚”。
项目延期:当时有 100+ 系统,系统之间高度耦合,且只有一套可供灰度验证的环境,导致出现一个项目延期,后续全部延期。
四大金刚:迭代发版全靠 4 个运维兄弟手动支持,虽然当时运维有使用工具平台,将发布收归脚本操作,但不同业务线的部署脚本五花八门,导致运维仍需要做一些编排的工作。运维人员疲于应付频繁的发布操作。疫情期间开发可以轮班,但运维不行。
明确需要优先解决的 2 个核心问题后紧接着就开始进行优化:一是让运维从频繁手动发布中解放出来,二是支持多灰度能力,解决单一链路的系统高耦合导致的连锁反应的问题,毕竟架构上的事情并不能马上解决。
1. 通过建设发布平台,让开发提交变更清单,运维只需要在发布平台进行简单编排即可完成发布和回退操作。同时结合运维平台能力,将服务粒度的部署脚本细化拆分成步骤和作业的方式。这样,一个类型的服务就可以通过组合指定的步骤形成一类的部署能力,发布平台只需进行绑定关联。
2. 通过 Nginx + Lua 的方式和目录形式,实现了业务的多灰度环境部署,同时结合多灰度的方式建立大小车的迭代模型。
在解决这两个问题的过程中,我们逐步意识到我们在做的事情和 DevOps 息息相关,开始深入去了解 DevOps 到底是个什么,同时也开启了 Devops 的第二阶段。
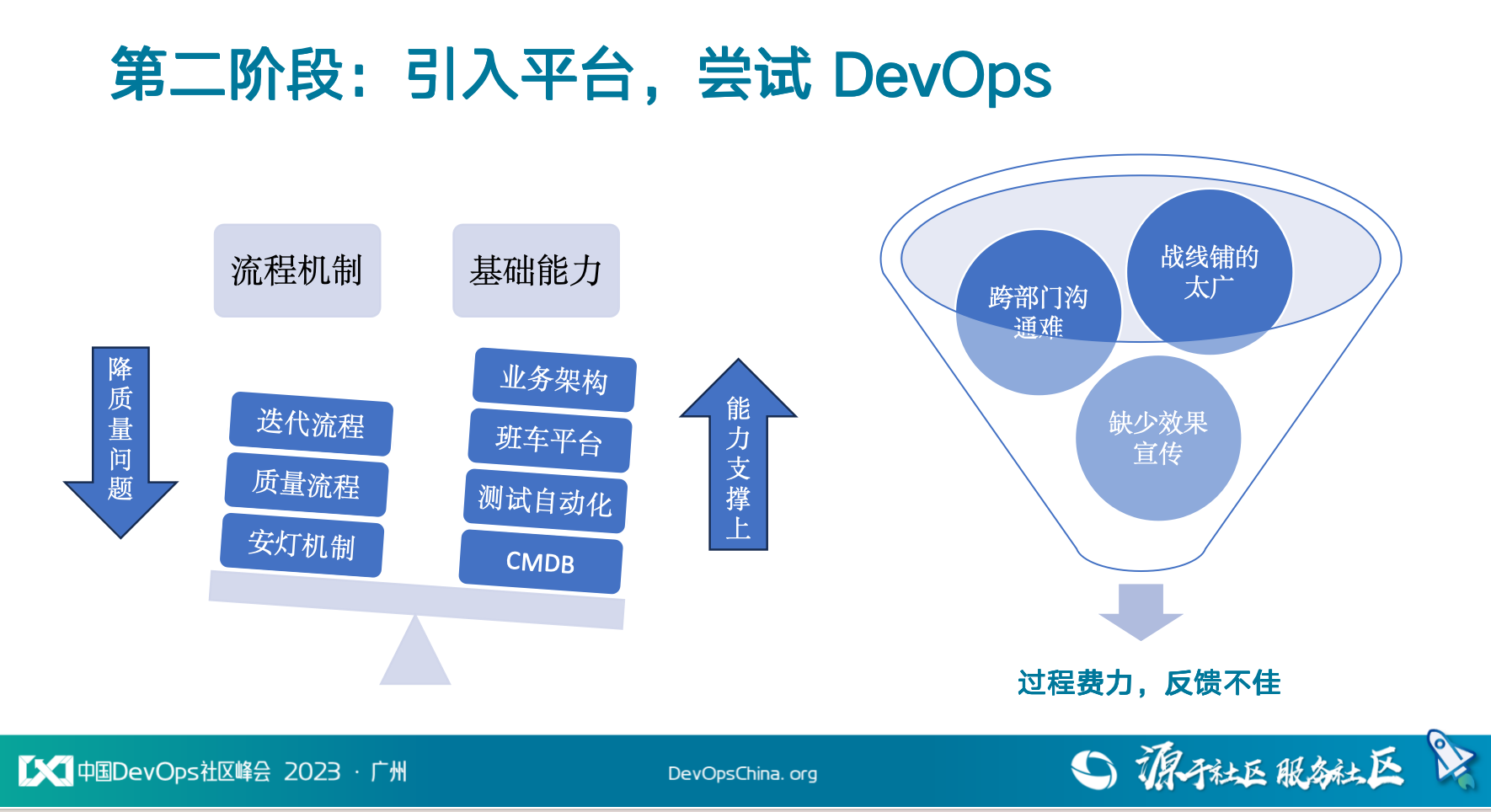
实施第一阶段的同时,公司业务保持快速增长,团队进入快速扩张的阶段,原本迭代慢的问题,随着人员的扩张和发布能力建设,短暂的平静一段时间后,很快新的问题随之而来。产研人员增长在达到 800+ 时,我们发现人员的增长不但没能带来预期的迭代增速,反而让整个产研变更混乱——协调沟通的声音盖过了鼠标键盘的声音。
我们从每个产研角色那都听到了不同的声音——起初所有的问题似乎都被人力不足所替代,但当人力上来后,其他的问题也就被推到了台面。这也再次证明了人力的增加并不一定有效提高产研能效。
由于业务架构的高耦合在迭代的过程中存在冲突,即使已支持多灰度,仍涉及较多的代码合并操作,最终导致业务沟通和测试验证工作激增。因此,大家希望业务重视架构设计,对已有不合理的耦合进行拆分解耦;而拆分后新服务的重新部署调试仍然需要运维参与。新服务部署后问题较多,影响项目交付。
此外,产品规划、方案评审、线上应急流程的缺失,都会加剧迭代过程中的问题。
这时,我们开始尝试用 DevOps 的方式解决问题。结合当时现状,我们梳理了一个完整的 DevOps 架构图,确定从几个不同的阶段,结合建立标准化、流程化、自动化来解决现有的问题:
1. 联合产研各部门,明确开发、测试、部署规范。
2. 联合项管、应急、客满团队,建立迭代、应急、按灯流程。
3. 业务侧开始对冲突严重的系统进行解耦拆分。
4. 结合工具逐步完善自动化能力。
这样,就初步搭起了小鹅的 DevOps 架子:规划阶段,使用单品项目管理工具建立需求管理、规划流程。开发阶段,结合 Git flow 以及 gitlab ci-runner 的能力进行构建管理和代码质量的扫描,与原有的发布流程打通。
虽然通过基础能力的建设和流程机制的完善,让迭代和质量的问题有所改善,但从最终的效果上并不好。主要体现在由于工具割裂,不同的角色使用不同的工具,跨部门沟通效率仍然不高;而且多工具维护成本高;数据割裂,无法整体度量改进。
随着 DevOps 工具链的接入,我们发现维护的成本较高,尤其是在大量并发的场景下,缺少经验丰富的人员工具链的问题解决效率低,与此同时,原本一些免费的平台逐步走向收费模式,这时我们希望引入一些商业化的平台,来加快我们效果的产出。因此我们开始深入产品的调研。
另一方面,在基于 CVM 的部署架构上,环境管理、发布变更、应急维护以及成本方面都有较多的诉求问题,全面容器化事项正式拉起。容器化本身对于产研团队来说是个较大的挑战,研发团队很多都不太了解容器、Kubernetes 相关的知识,而且容器申明式部署和以往CVM有很大的不同。但我们认为这可能会是一个比较好的机会,我们可以通过平台降低掉云原生相关技术的学习成本,让研发人员几乎可以像之前一样使用平台,而无须关注底层技术的实现,同时也将我们的 Devops 落地实践结合起来,完善整体的能力建设。
与此同时,我们也重新回归到价值流的关注上。通过流程、平台的建设完善整个发布迭代的闭环。同时结合小鹅“客户第一”的宗旨,未来将客户也纳入到价值环中,通过客户对于交付的迭代进行评估价值点,以期望让整个假置换能够进入到一个正向循环中,以不断的解决客户问题为核心。
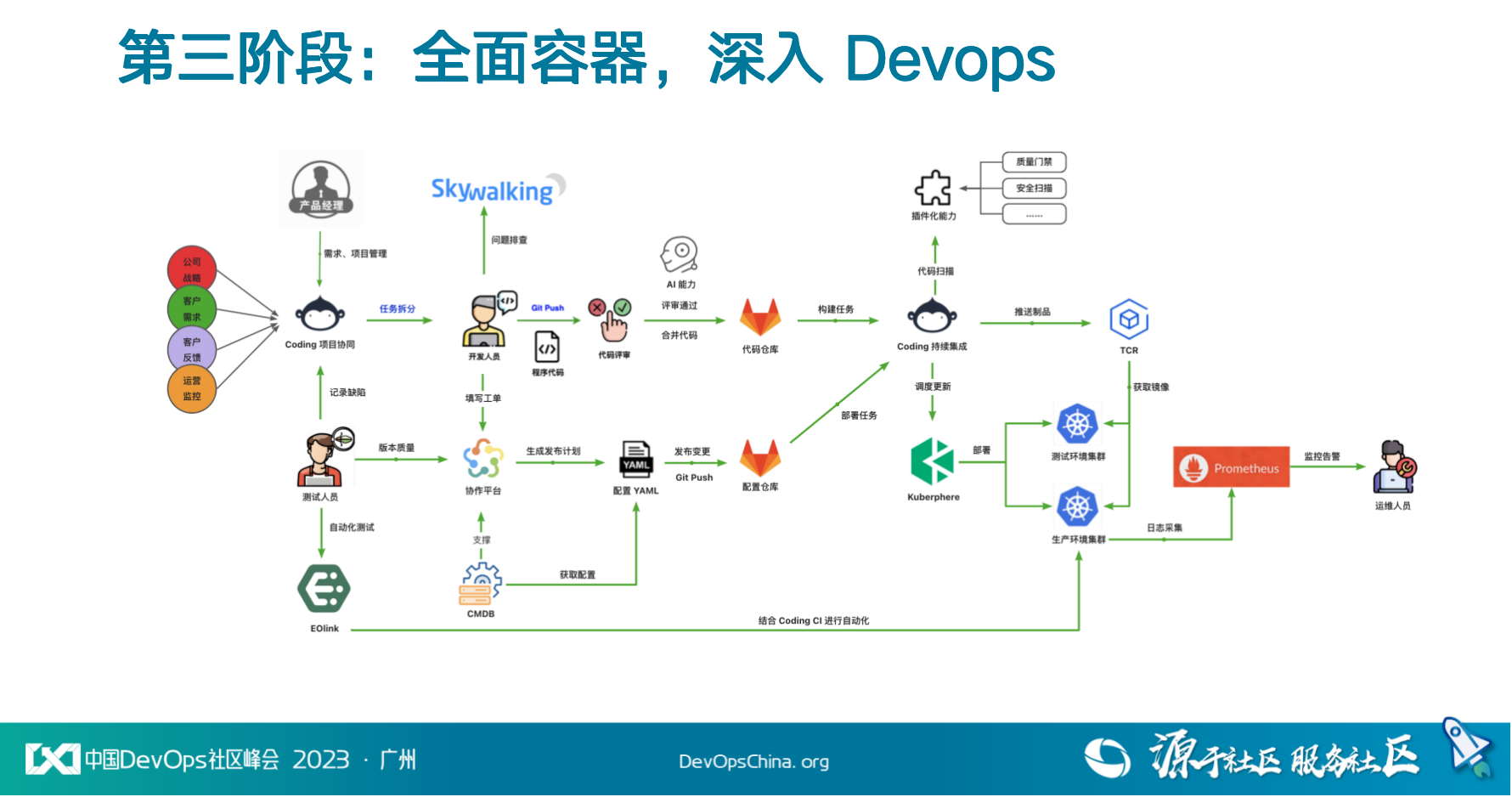
因此第三阶段的目标也逐渐清晰——结合容器化,彻底解决标准化的问题;同时深入实践 DevOps 价值流。在这个阶段,我们全面开始使用腾讯云 CODING DevOps:
整合原有小鹅社区、单品项目管理中的需求/缺陷,统一收口迁移至 CODING 项目协同,利用 CODING 项目协同进行业务需求管理。
基于CODING 项目协同、代码仓库、代码扫描、持续集成、制品仓库的产品能力与小鹅通内部存量 Gitlab 仓库管理进行整合,融入 K8S 集群、Prometheus、CMDB 等企业内原有发布系统。
最终,初步实现需求全生命周期端到端的安全交付管理,极大提升研发交付效率。未来也计划基于 CODING 生态和内部系统整合实现持续运营能力的建设。
一些思考
插拔式能力
DevOps 在国内发展的今天,也越来越被大家重视,特别是在这几年大环境的挑战下,降本增效一再被提及,行业内开始关注一站式的 DevOps 能力,渐渐的有同质化的竞争。但每个企业各具差异,很难统一,大团队流程相对完善,牵一发动全身,决策成本高,其中有研发能力的团队,可能会做很多定制化;小团队对于价格敏感,同时一站式的完整理念不一定在适配当前的团队现状。因此建议厂商对某些场景或问题深入挖掘,具备插拔式能力来提供服务,从而降低实践 DevOps 的成本。
DevOps 的愿景
最近在读《埃隆马斯克传》,其中马斯克的想法让我也有一些思考,对于 DevOps 的理解希望不仅仅是在我们的企业、团队去时间落地,同时也希望通过社区的传播让 DevOps 的理念在国内能够更好的传播。目前大家都觉得国内的环境很卷,而且在创造价值的过程中因为各种问题产生大量的内耗,最终对整个社会的价值创造低于原有预期,DevOps 的普及是否能够去影响整体的环境呢?